


I think OpenAI is not being honest about the diminishing returns of scaling AI with data and compute alone. I think they are also putting a lot of the economy, the world and this entire industry in jeopardy by not talking more openly about the topic.
At first, I believed what they told us, that all you need to do is add more compute power and more data, and LLMs as well as other models will simply get better. That this relationship between the models, their compute and data could grow linearly until the end of time. The leap from GPT-3 and GPT-3.5 was immense. The leap from GPT-3.5 to GPT-4 seemed like clear evidence that this presumption was correct. But then things got weird.
Instead of releasing a model called GPT-5 or even GPT-4.5, they released GPT-4-turbo. GPT-4-turbo is not as intelligent as GPT-4 but it is much faster and it’s cheaper. That all makes sense. But then, this trend kept going.
After GPT-4-turbo, OpenAI’s next release was GPT-4o. GPt-4o is more or less just as intelligent as GPT-4-turbo, but it is even faster and even cheaper. The functionality that really sold us, however, was its ability to talk and understand things via audio and its speed. However, take note, at this point in our story, GPT-4-turbo is not more intelligent than GPT-4 and GPT-4o is not more intelligent than GPT-4-turbo. And none of them are more intelligent than GPT-4.
Their next and most recent release was GPT-o1. GPT-o1 can perform better than GPT-4 onsome tasks. But that’s because o1 is not really a single model. GPT-o1 is actually a black box of multiple lightweight LLM models working together. Perhaps o1 is even better described as software or middleware than it is an actual model. You give it a question, it comes up with an answer, and then it repeatedly uses other models tasked with checking the answer to make sure it’s right, and it disguises all of these operations. It does all of this very, very quickly.
Why not just make an LLM that’s more powerful than GPT-4? Why resort to such cloak-and-dagger techniques to achieve new releases? GPT-4 came out 2 years ago, we should be well beyond its capabilities by now. Well, Noam Brown, a researcher at OpenAI had something to say on why they went this route with o1 at TED AI. He said “It turned out that having a bot think for just 20 seconds in a hand of poker got the same boosting performance as scaling up the model by 100,000x and training it for 100,000 times longer,”
Now stop and really think about what is being said there. A bot thinking for 20 seconds is as good as a bot trained 100,000 times longer with 100,000 times more computing power. If the scaling laws are infinite, that math is impossible. Something is either wrong here or someone is lying.
Why does all of this matter? OpenAI is worth 150 billion dollars and the majority of that market cap is based on projections that depend on the improvement of models over time. If AI is only as good as it is today, that’s still an interesting future, but that’s not what’s being sold to investors by AI companies whose entire IP is their model. That also changes the product roadmap of many other companies that depend on the continued advancement of their LLMs to build their own products. OpenAI’s goal and ambitions of AGI are severely delayed if this is all true.
A Hypothesis
The reason LLMs are so amazing is because of a higher level philosophical phenomenon that we never considered, that language inherently possesses an extremely large amount of context and data about the world within even small sections of text. Unlike pixels in a picture or video, words in a sentence implicitly describe one another. A completely cohesive sentence is by definition, “rational”. Whether or not it’s true is a very different story and a problem that transcends language alone. No matter how much text you consume, “truth” and “falsehoods” are not simply linguistic concepts. You can say something is completely rational but in no way “true”. It is at this point LLMs will consistently hit a brick wall. Over the last 12 months, I’d like to formally speculate that behind closed doors there have been no huge leaps in LLMs at OpenAI, GrokAI, or at Google. To be specific I don’t think anyone, anywhere has made any LLM that is even 1.5X better than GPT-4.
At OpenAI it seems that high-level staff are quitting. Right now they’re saying it’s because of safety but I’m going to put my tinfoil hat on now and throw an idea out there. They are aware of this issue and they’re jumping ship before it’s too late.
Confirmation
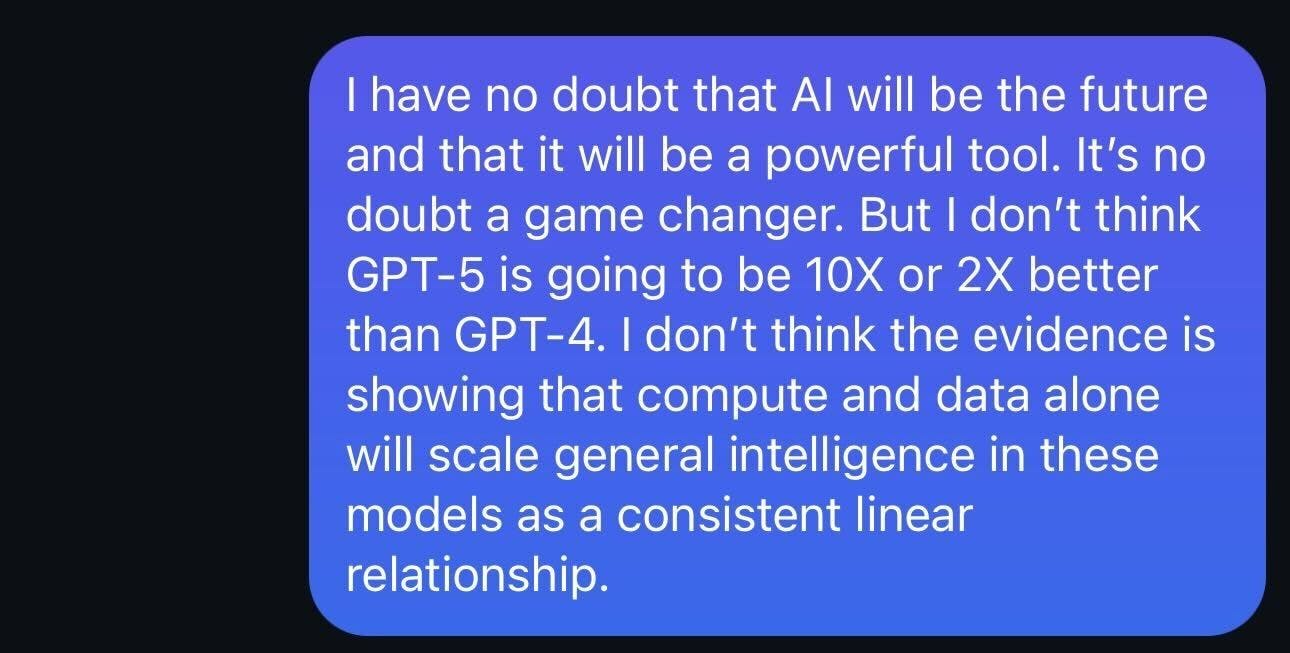
I started discussing this concern with friends 3 months ago. I was called many names haha.

A text message I sent my friend on July 18, 2024
But in the last 3 weeks, a lot of the press has begun to smell something fishy:
- OpenAI is no longer releasing Orion (GPT-5) because it did not meet expected performance benchmarks and it is seeing diminishing returns. (https://www.theinformation.com/articles/openai-shifts-strategy-as-rate-of-gpt-ai-improvements-slows)
- Bloomberg reports that OpenAI, Google and Anthropic are all having struggles making more advanced AI. (https://www.bloomberg.com/news/articles/2024-11-13/openai-google-and-anthropic-are-struggling-to-build-more-advanced-ai)
What can we do about it?
It’s hard to recommend a single solution. The tech behind o1 is proof that even low-performance models can be repurposed to do complicated operations. But that is not a solution to the problem of AI scaling. I think there needs to be substantial investment and rapid testing of new model architectures. We also have run out of data and need new ways of extrapolating usable data for LLMs to be trained on. Perhaps using multidimensional labeling that helps guide its references for truthful information directly. Another good idea could be to simply continue fine-tuning LLMs for specific use cases like math, science, and healthcare running and using AI agent workflows, similar to o1. It might give a lot of companies wiggle room until a new architecture arises. This problem is really bad but I think that the creativity in machine learning and software development it will inspire will be immense. Once we get over this hurdle, we’ll certainly be well on schedule for AGI and perhaps ASI.
This article was originally published by Dossey Richards III on HackerNoon.








{kind=link}