


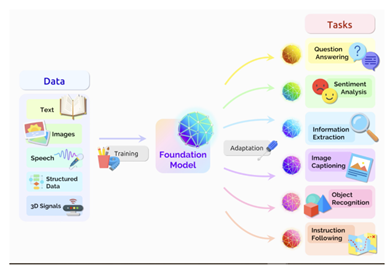
Large language models (LLMs) such as GPT-3 have rapidly become one of the most significant technological advancements in the field of natural language processing (NLP).
LLMs have demonstrated significant potential to assist in a variety of tasks, including language translation, text summarization, question answering, information retrieval, recommendation engine, language grounded robotics, and many others.
While Large Language Models (LLMs) like ChatGPT have shown exceptional performance in various natural language processing tasks, their potential misuse raises ethical concerns that must be addressed. With the ability to generate coherent and contextually relevant text, LLMs could be used to produce fake news or spread misinformation, which could have severe consequences on society.
Such misuse could lead to the erosion of trust in news media and a distorted perception of reality. Additionally, LLMs could be utilized for plagiarism, intellectual property theft, or fake product reviews generations, which could mislead consumers and impact businesses negatively. Moreover, the ability of LLMs to manipulate web content for malicious purposes, such as creating fake social media accounts or influencing online discussions, could have disastrous effects on public opinion and political discourse. With the growing concern, it’s probably about time to ask the question: Can we discern AI-generated texts from Human-generated ones?
Past Research & Detectability
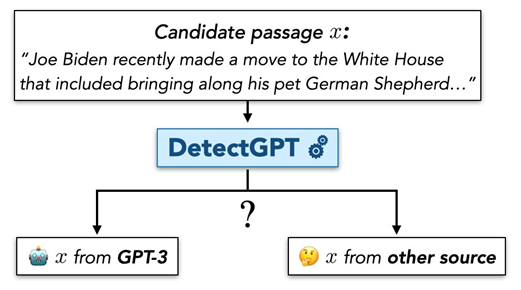
On one hand, DetectGPT from Stanford compares the probability that a model assigns to the written text to that of a modification of the text, to detect.
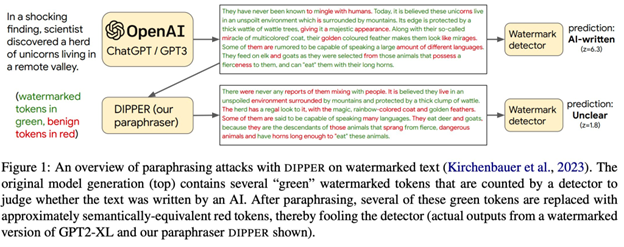
On the other hand, watermark-based approaches developed by Tom Goldstein’s group are proposed to effectively increase detectability.

However, watermarks (that are not robustly trained) have been shown to be vulnerable to paraphrase and spoofing attacks, by Sadasivan et al. and Krishna et al.
Latest Debate in the Community
The community has been lately having a heated debate about whether AI-generated texts can be discerned from Human-generated ones, along with discussions on whether we will fail to ‘retain the AI’ and have an AGI apocalypse since we cannot detect the AI-generated content. Tech leaders even called for a 6-month suspension of large language model (LLM) training. Academic leaders such as Yann Lecun and Andrew Ng are against this ban on AI.
VP and Chief AI Scientist at Meta, Yann LeCun quotes, “Why slow down the progress of knowledge?”
Possibility of Detection
Amidst this critical time, we study detectability of AI-generated texts through an information theory lens. We provide evidence for optimism: it should almost always be possible to detect unless human and machine text distributions are exactly the same over the entire support.
Detectability is Possible
The detectability relies on a precise trade-off with Chernoff Information and more observations. We prove an attainable upper bound of AUROC (which is between 0 and 1, higher means more detectable) via a likelihood-ratio-based detector using multiple samples. As the sample # increases, AUROC increases exponentially to 1.
An Information Directed Lens
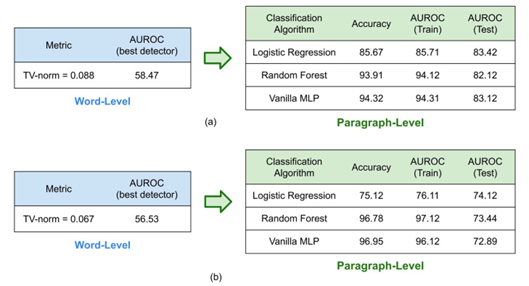
This information theoretical results rely on a key quantity called Chernoff information, which may guide the design of watermarks of LLMs. Experimentally, we have verified that undetectability of word-level detection becomes detectable when switched to paragraph-level detection.
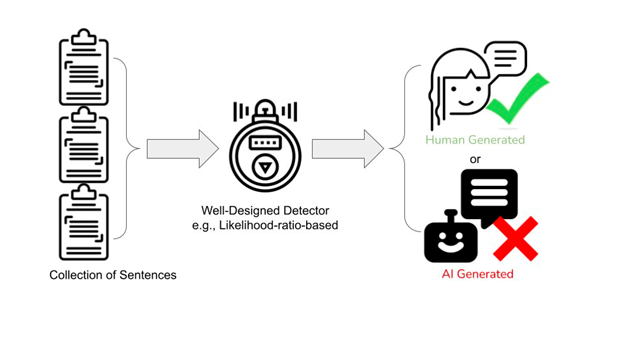
Our results demonstrate that it will be almost always possible to detect AI Generated Text.
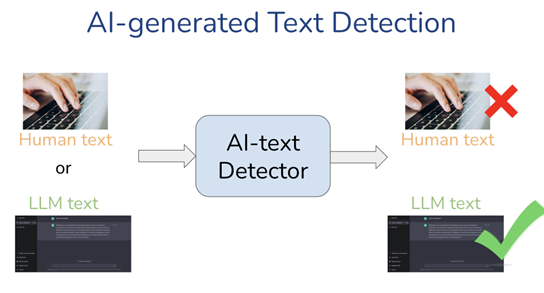
Theoretical Results
This information theoretical results rely on a key quantity called Chernoff information, which may guide the design of Watermarks of LLMs. We derived sample complexity bounds to guide the possibility of AI-generated text detection.

Empirical Demonstrations
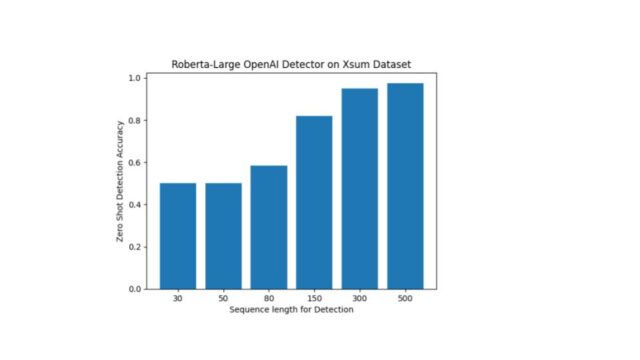
Undetectability at word level becomes detectable when switched to paragraph-level detection on multiple datasets. As we increase the length of the detection, the ZeroShot detection accuracy increases significantly.
In the end we believe the right way to deal with misuse of #LLMs is to fix them rather than ban them.
Even as a youngster, though, I could not bring myself to believe that if knowledge presented danger, the solution was ignorance. To me, it always seemed that the solution had to be wisdom. You did not refuse to look at danger, rather you learned how to handle it safely.
Isaac Asimov
Note: This is the first step and our study calls out continued research to develop frameworks and guidelines that prompt innovation and ensure ethical use of these powerful tools.
Guest contributors:
Souradip Chakraborty, Ph.D. Grad Student at University of Maryland, Amrit Singh Bedi, Research Scientist, University of Maryland, Sicheng Zhu, Bang An, Dinesh Manocha, and Furong Huang are researching detectability of AI-generated texts through an information theory lens. Any opinions expressed in this article are strictly that of the authors.








