

Overview
Spark. Storm. Madness. A lot’s been happening in the last six months in terms of large language models (LLMs). They’re being published, adapted, improved, disseminated, and applied. People quickly began to adopt LLMs in their daily lives and work, no longer seeing a way back without these AI-powered instruments.
A large language model (LLM) is a type of AI algorithm that uses deep learning techniques and massively large datasets to understand, summarize, generate, and predict new content. One of the key aspects of creating an LLM is, of course, data?—?a huge amount of data. Data collection must be structured and divided into categories depending on the subtask that a subcategory solves. Subsequently, one by one, they’re filled with gigabytes of data.
However, to solve some of these subtasks, it’s not enough to simply pump out an X amount of data. An analysis or other qualitative assessment is also necessary since the quality of the final model depends on it. One way to achieve this is to use crowdsourcing.
This article addresses how to collect data for a text summarization task via crowdsourcing?—?using Toloka as an example to solve a specific subtask.
Text summarization pipeline
Before diving into this pipeline, we recommend reviewing some of our basic tutorials.
Let’s start by creating a dataset of summarized texts using crowdsourcing.
Project 1, Stage 1: Text summary
Start by screening annotators based on their language proficiency and relevant skills using the platform’s filters and language tests. This helps ensure that only the most qualified annotators work on your tasks. In Toloka, annotators are called Tolokers.
In our example, we’ll use the top 30% of Tolokers who pass two tests:
· An English test
· A monthly grammar test
Both of these tests are built into the platform. See Figure 1 below for more details.
Tolokers can also be filtered by custom skill, so we’ll accept Tolokers who have the text_summarization_test skill. In general, the text_summarization_test skill marks Tolokers who have already proven themselves to be good summary writers or who have just joined the task and don’t have a record of answers yet.
Once Tolokers are selected, we give them texts to summarize. You can see all the project settings in Figure 1.
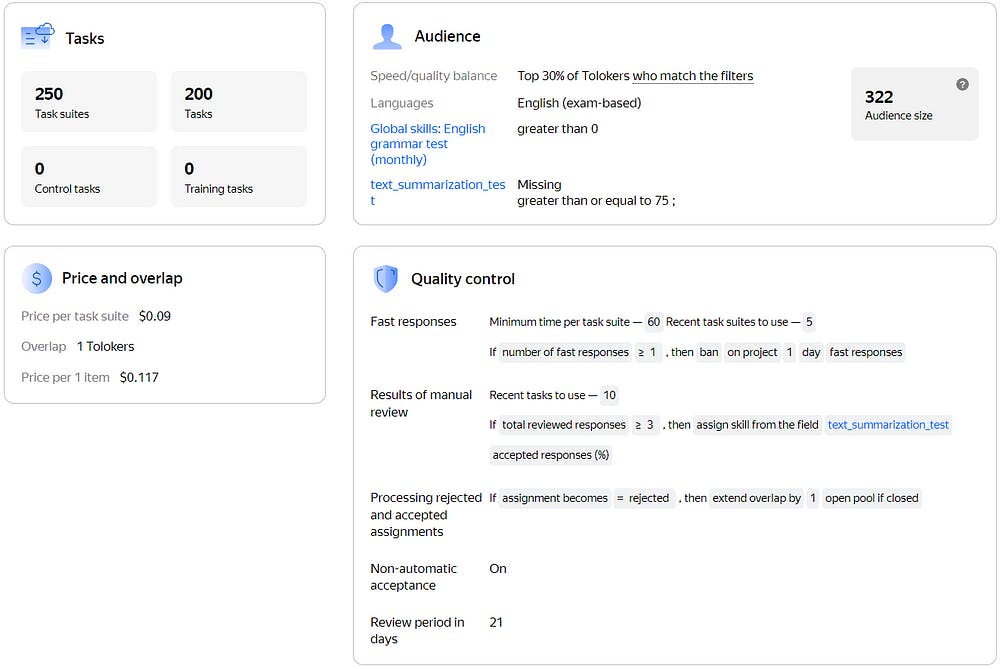
Figure 1. Image by the author.
To ensure high-quality output, we’ve implemented two rules regarding the post-acceptance process for manually reviewing and approving submitted summaries:
- Once Toloker has provided three responses, we check the quality of their summaries in a validation project. This is referred to as the text_summarization_test skill in the Toloker filter above, which only accepts annotators whose response acceptance rate is higher than 75%. It is important that we start counting this skill only when the Toloker reaches a minimum of 3 responses to give them an opportunity to prove themselves.
- If the task is not accepted, we expand the overlap and give the next Toloker a chance to work on the task.
Project 2: Validating summary quality
From here, we’ve created a validation project to assess the quality of summaries based on several factors: harmlessness, truthfulness, helpfulness, and fluency. Just like before, we use filters and language tests to select the best validators.
Additionally, for better results, we provide Tolokers with training and an exam to make sure that they fully understand the task. We also use control tasks to monitor validators. Figure 2 shows the basic pipeline. Figure 3 shows all the settings.
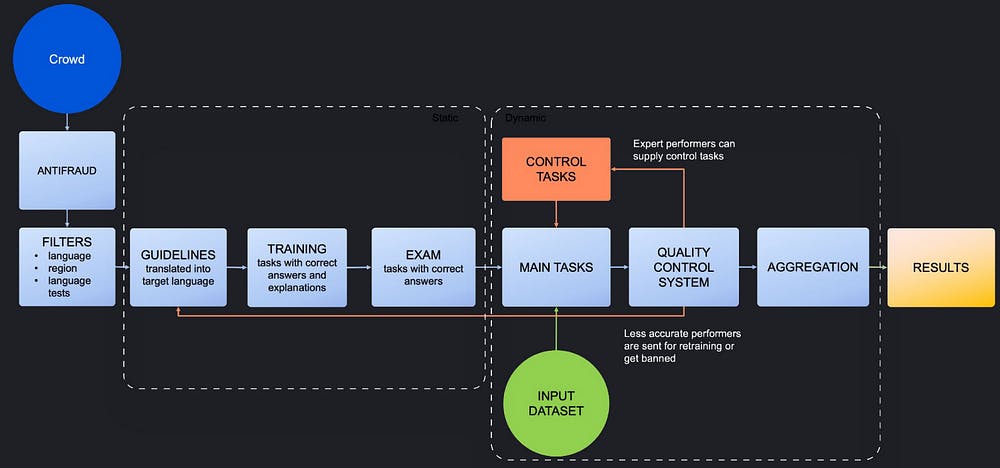
Figure 2. Image by the author.
Only Tolokers with high scores on the exam are allowed to work on the main task. The exam score is indicated in the sum_val_test_exam skill as a percentage of correct answers, with a set threshold for the filter.
We also use control tasks during the main labeling process and track the accuracy rate using the sum_val_test skill. We use it as an additional filter to select the most accurate annotators.
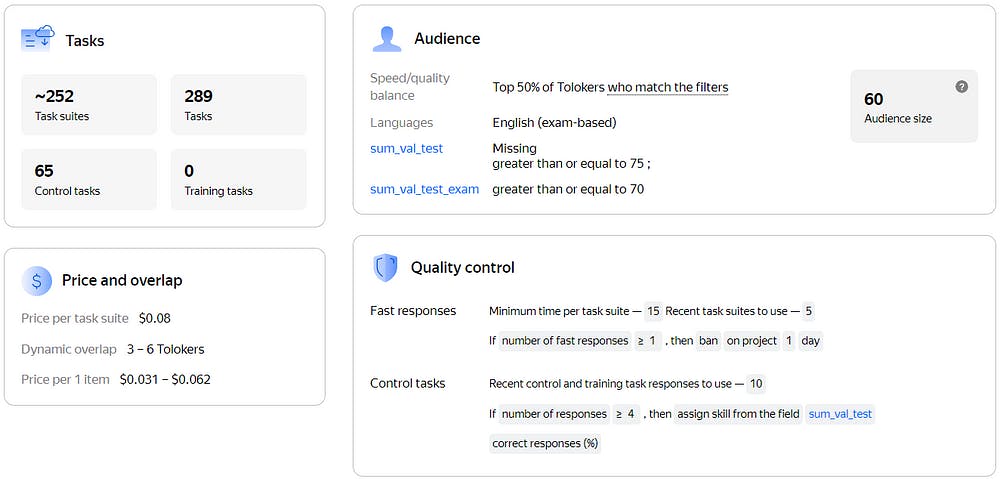
Figure 3. Image by the author.
Project 1, Stage 2: Text summary acceptance and rejection
Let’s go back to the first project. After validation, we accept or reject the summaries, calculating the acceptance rate for each performer and keeping only the best writers on board.
Results
That’s it! We’ve obtained the necessary data and now we just need to download it. Here’s an example of an accepted task:
Article
Rangers have promised to probe claims Mike Ashley has grabbed control of the club’s badges. Reports emerged on social media on Thursday afternoon suggesting the Newcastle United owner was now the official owner of the Light Blues trademarks?—?including the ‘Ready’ badge and mascot Broxi Bear.
The Sports Direct tycoon had been given security over the icons and logos as part of the £ 5 million loan handed to the previous Gers board in January. Rangers have promised to probe claims Mike Ashley has grabbed control of the club’s badges. Reports emerged suggesting the Newcastle owner was now the official owner of the Light Blues trademarks.
But now Dave King’s new regime has promised a speedy investigation after documents appeared on the government-run Intellectual Property Office (IPO) website showing the club’s trademarks were now controlled by SportsDirect.com Retail Ltd. In a statement, a club spokesman said: ‘The board is currently conducting a review of all contractual documentation but this particular issue has become a matter of urgency.’
News that Ashley has seized hold of more treasured assets will worry the Ibrox faithful. The Londoner is already vastly unpopular after grabbing hold of a 75 percent share of the club’s retail income with his loan deal. Dave King’s new regime has promised a speedy investigation into the claims surrounding Ashley.
The IPO site confirm the transfer from Rangers Football Club Ltd to Sports Direct was fully assigned on March 25?—?less than three weeks after former chief executive and Ashley ally Derek Llambias and finance director Barry Leach, a former Sports Direct executive, were removed at a general meeting called by King. Yet Interim chairman Paul Murray announced two days later that the new board had held ‘no discussions with Mike Ashley or Sports Direct’.
Rangers announced last week that if they gain promotion to the Premiership, they will have to pay Newcastle £500,000 as part of the deal which saw five Magpies youngsters move to Ibrox on loan.
Ashley was given security over the icons and logos as part of the £5m loan handed to the previous board.
Toloker summary
On Thursday afternoon, reports surfaced on social media that the owner of Newcastle United had become the official owner of the Light Blues’ trademarks, including the “Ready” badge and the mascot, the Broxy Bear. The Rangers have vowed to investigate allegations that Mike Ashley seized control of the club’s emblems. In a statement, a club spokesman said: “The board is currently reviewing all contract documents, but this particular issue has become urgent.”
As you can see, this summary is quite good and reflects the essence of the text.
Bonus: Comparison with an LLM
We conducted further research by comparing the text summarization results of Tolokers with our Bart-large model. We asked Tolokers to choose between two summaries without telling them which one was written by a human and which one was generated by the LLM. We discovered that 78% of the time Tolokers preferred the summary written by a human rather than the model. While state-of-the-art models have achieved a lot, there is still work to be done. One day machines may even surpass humanity.
Below you can see the summary of the same article by our Bart-large model.
LLM summary:
Rangers have promised to probe claims Mike Ashley has grabbed control of the club’s badges. Sports Direct tycoon had been given security over the icons and logos as part of a £5m loan handed to the previous Gers board in January. But now Dave King’s new regime has promised a speedy investigation after documents appeared on the government-run Intellectual Property Office (IPO) website.
Conclusion
In this article, we looked at how to collect data for LLMs through a text summarization challenge. We reviewed each step of our pipeline and explained the nuances of working with crowdsourcing. Also, we compared our results with one of the most popular LLM models and discovered that there is still a long way to go to achieve accurate results.
In the end, we got the training data we needed. The next step should be to train the model on this data to solve the specific task of text summarization.
This article was originally published by Fraltsov Denis on Hackernoon.








{kind=link}
{kind=link}
{kind=link}